
一般に機械学習=深層学習、ニューラルネットワークのようなイメージがある。最近の生成AIに代表的な話であるが、一方機械学習でありながらニューラルネットワークを殆ど用いてこなかった分野もある。これがいわゆる表形式データで、Excelのワークシートをイメージしてもらうとわかりやすい。Materials Infomaticsは通常この表形式データを用いるが、回帰分析手法はRF(ランダムフォレスト)やXGB(eXtreme Gradient Boosting)、LGBM(Light Gradient Boosting Machine)のような、決定木系のものが多く使用される。
これは、ニューラルネットワークがビッグデータに対して効果を発揮するもので、概ね1万とか以上のデータに有用である。実験を1万単位で実行することは大量の時間やリソースを必要とするため、表形式データのデータ数は数百~高々数千個であることが殆どで、ここでは決定木系のアルゴリズムが力を発揮する。しかし、XGB, LGBMのようなアルゴリズムが発表されたのは2016-2017年であり、7-8年前の技術が適用されていたことになる。
そこで、Chat-GPTに最近の回帰アルゴリズムって何があるの? と投げかけてみた。その結果が下の図となる。
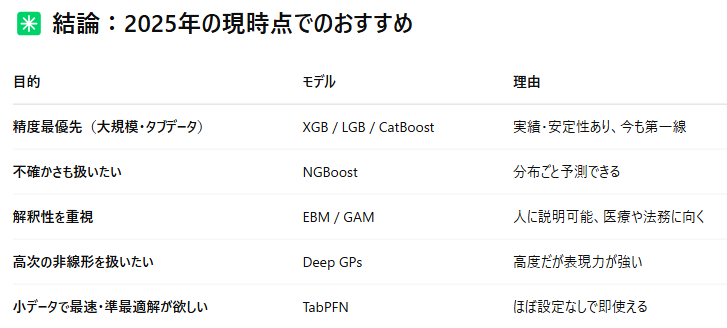
あまり聞いたことのない手法が並んでいたため、それぞれについて少し調べてみた。NGBoostも決定木系の手法の1つだが、分布を予測できるのが特徴となる。EBMはデータの解釈に重きを置いた手法で、Deep GPsはガウス過程回帰の進化版という感じであった。上に書いているように高度で使いこなすには少し学習コストがかかりそうである。一番下にTabPFNというものが出ており、以下はこのアルゴリズムについての記載となる。
TabPFNは、今年(2025年)の始めにNatureで報告された。ドイツの大学からのもので、表形式データにニューラルネットワークを適用して高精度を達成するという話となっている。下はNatureのサイトからのもの。
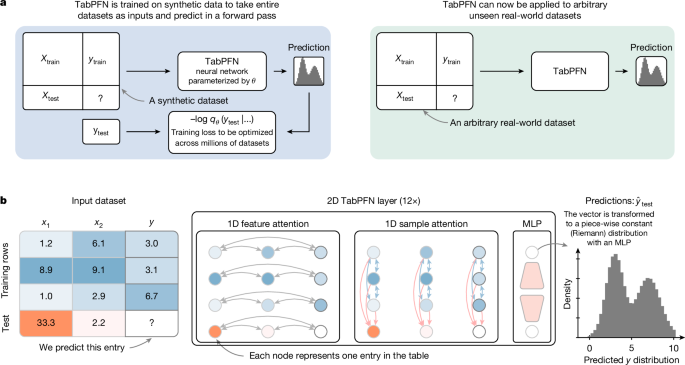
ここでいうSmall dataとは、10000個以下、説明変数500個以下のものを意味し、まさにMaterials Infomaticsが扱う大きさに合致する。タスクとしては、分類、回帰のどちらにも対応している。どうやってニューラルネットワークを適用したかというと、大量の疑似的な実験データとその解を準備して、それをTransformerで学習させた、ということらしい。大量に学習しているため、新しい実験データが来ても学習済みのパターンと照らし合わせて予測する、という仕組みのようだ。
このTabPFNの特徴は以下となる。1つは先に述べたように小規模データで高速かつ高精度に動作すること、次にGPUを用いることでさらに高速化できること、3つ目は予測値として確率分布に近いものを示すことができるためベイズ最適化に適用できること、4つ目どの説明変数が性能に寄与するかを示すSHAP値を出力できること、などとなる。これが本当ならばいいことづくめである。
実際に使用して回帰性能や実行速度等を検証してみたが、長くなったのでそれは次回とする。

コメント