
会社では材料科学系の研究職をしている。その中で個人的に最も興味がある事象は『拡散』である。例えば金属Aの表面に異種金属Bをくっつけた後に熱をかけるとAとBとはお互いに拡散する。
この『拡散現象』については、Fickの第一法則と第二法則で記述されることがわかっている。詳細は割愛するがFickの第二法則から導かれる式は以下となる。
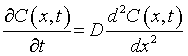
Cは金属濃度、xは位置、tは時間、Dは拡散係数となる。この式を解くとある時間、ある位置における金属AとBの濃度を計算できる。
上の式は偏微分方程式で解析的に解くのが難しいこともあり、コンピュータを用いて数値的に解かれることも多い。この拡散計算に関するPythonライブラリが幾つかあり、私は最近Pydiffusionを使用している。

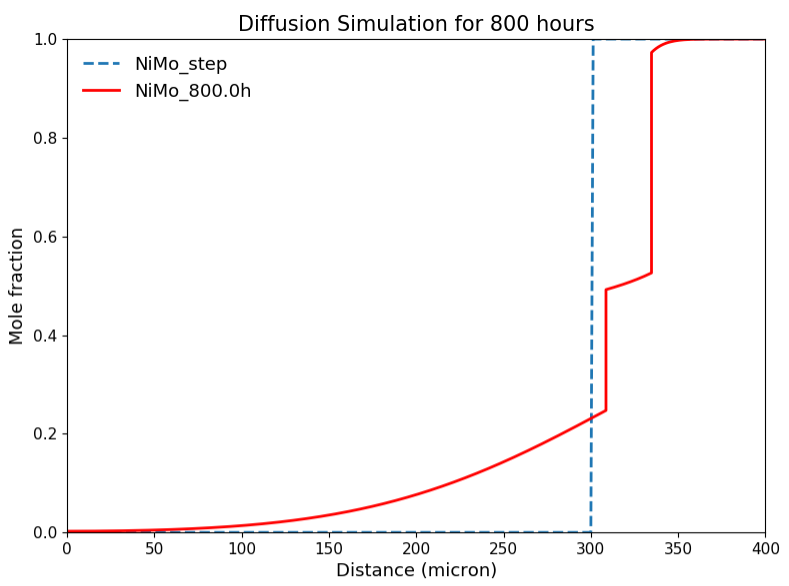
これを使用すると相互拡散係数と濃度分布を比較的簡単に計算できる。下はPydiffusionの公式ガイドに記載されているNi−Mo系の計算例で縦軸はNi濃度を示す。
さて、ここまでは物理現象の『拡散』にITを利用しましたという話で特に珍しい話ではないが、考えてみると最近のデータサイエンスの世界も実は類似の事象を扱っているのではないか? という気がしてきた。
変化量として色々なものに着目する場合があり、例えばTwitterの投稿だったり、株価だったり、写真だったりするのだろうけど、わかりやすく株価で考えると、株価の過去のトレンドから未来を予測したい、というのがデータ解析の目的となる。何か新しい製品(スマホ等)が普及していく現象を捉えようとすると二次元的な広がりと経時的な情報を両方解析する必要がある。
これは正に物質的な拡散と同じで、上に記載した偏微分方程式は位置情報と時間情報を含んでいる。計算で得られる結果も上の図のように得られ、時間を固定したときの位置と元素濃度が図示されている。
結局のところ、縦軸となる変化量の位置分布もしくは経時での予報を得たい訳で、これは物質の拡散現象で得たいものと変化量が異なるだけで同じことである。ということは、拡散現象を扱って得られた知見なりスキルはデータサイエンスの世界でも活用できるのかもしれない。
#拡散 #データサイエンス #Pydiffusion

コメント